Technical Insights & Tutorials
Deep dives into model optimization, HPC, MLOps, DevOps, and production-grade AI/ML engineering.
Blogs
Our most popular and in-depth technical guides

We Benchmarked LLMs on a $499 Jetson Orin Nano: 158 Tokens/sec at 8 Watts — and Where the Board Breaks
We load-tested Gemma 3 on a Jetson Orin Nano 8GB: measured throughput, latency, and power from 1 to 16 concurrent users — including the configs that failed.

The Token Tax: A Comparative Audit of Inference Optimization Techniques
We benchmarked Llama 3 70B across FP16, INT8 quantization, and KV-cache pruning on H100 and A100 GPUs. The results: 42% lower cost per million tokens and 2.3x throughput — without quality loss you'd notice in production.

Embedding Rerank Gateway: Rust vs Python Cost and Performance
Hugging Face Python vs Rust ONNX: we built the same embedding + rerank gateway in both. Rust hit 28% more RPS with 67% less memory, lowering RAG infrastructure cost.
View all posts
12 articles published
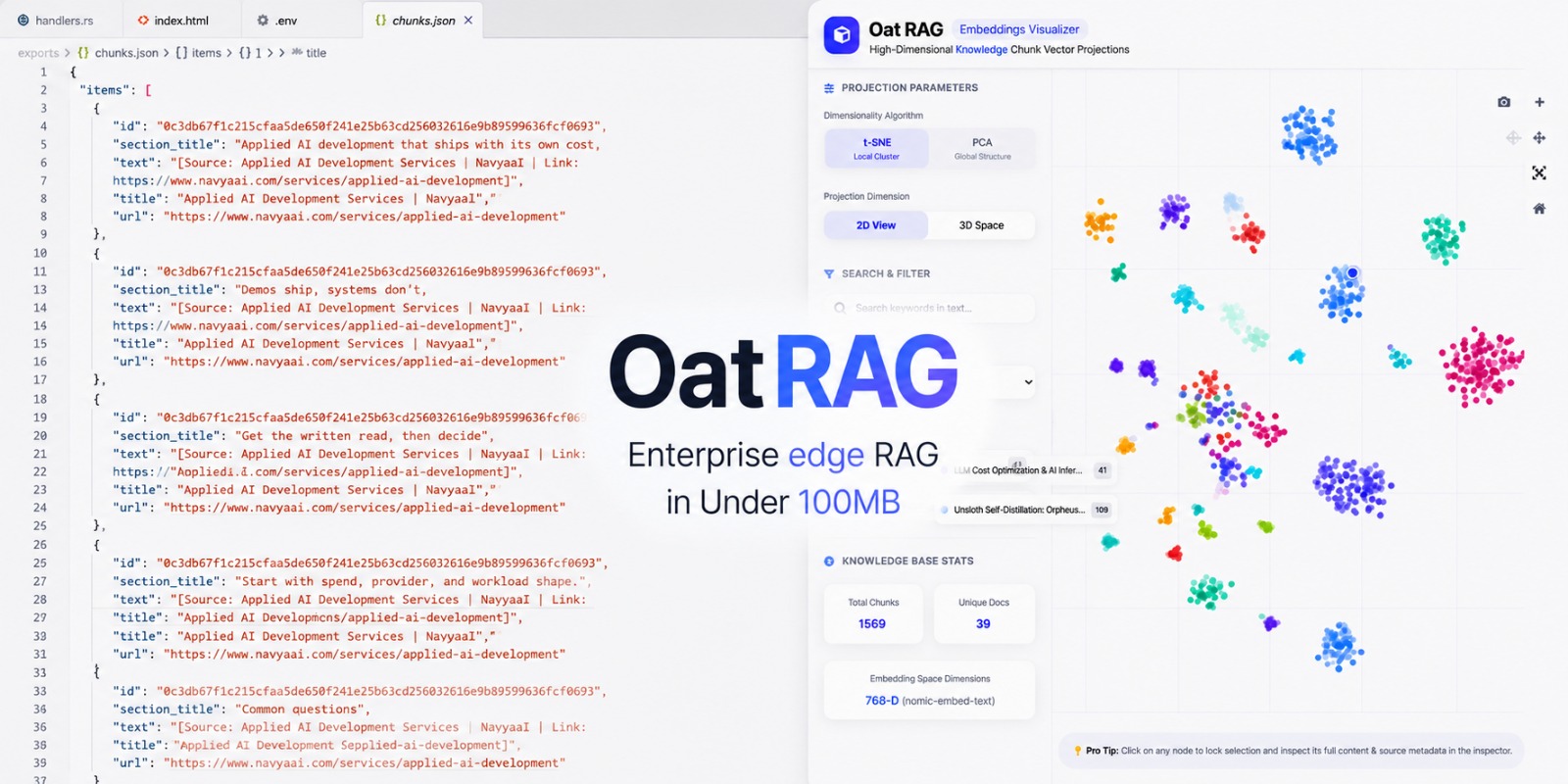
OatRAG on Jetson Orin Nano: Enterprise RAG in Under 100MB
We ran a full RAG stack on an NVIDIA Jetson Orin Nano in 90 MB — an 84.8% memory cut vs a traditional stack, leaving 6.45 GB free for the LLM.
Cloud Egress Costs: The Hidden Tax Breaking Cloud Budgets (and How to Cut It 20–80%)
Egress is rarely one line item — it's internet-out, NAT, cross-AZ, cross-region, CDN cache-fill, and realtime fanout. We break down list pricing across AWS, GCP, Azure, Supabase, Neon and Cloudflare, model four workloads, and show why your biggest network cost is architectural, not the rate card.
Oat UI: Semantic HTML UI Library and React Alternative
Oat UI is a lightweight semantic HTML UI library for building fast, browser-native interfaces without React, utility classes, or build tooling.

Claude Mythos and Project Glasswing: The Morning an AI Found a 27-Year-Old Bug in OpenBSD
Claude Mythos found a 27-year-old OpenBSD bug and a 16-year-old FFmpeg flaw that five million fuzzing runs missed. What Project Glasswing means for your security work this week.
Designing Software for AI Agents: Why Your CLI and API Now Have Two Readers
A warning I saw in a CLI last week points at the biggest shift in software design since cloud. Software now has two readers: humans and AI agents. Here's what that actually means for your CLIs, APIs, docs, and cost structure, with the patterns and pitfalls we've learned building agent-native interfaces at NavyaAI.
Threads Beat Multiprocessing for RAG: 70% Faster, 75% Less Memory
We benchmarked RAG ingestion across Python 3.13, 3.14, and 3.14t. Threads are 70% faster than multiprocessing with 75% less memory — because NumPy and PyTorch already release the GIL. Your infra doesn't need more pods.

Python vs Rust for Transformers: Performance and Cost
We load-tested Python FastAPI vs Rust Axum for GPU transformer inference. Rust delivered lower latency, higher throughput, and better cost per production request.
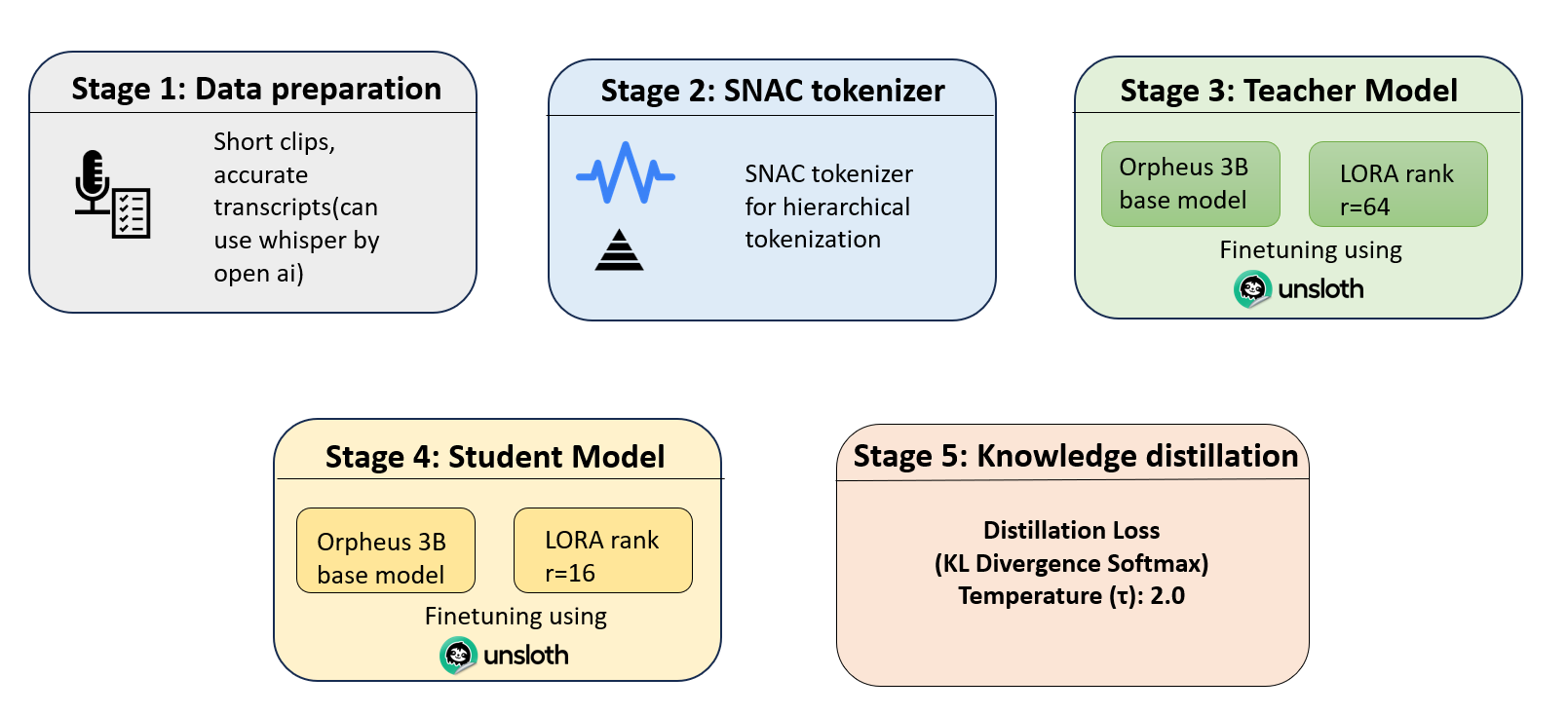
Self-Knowledge Distillation for AI Efficiency: Orpheus TTS
Unsloth distillation walkthrough: compress Orpheus-3B TTS with self-knowledge distillation, SNAC tokenization, and LoRA to cut serving memory and private AI deployment cost.

Python 3.14 No-GIL vs Rust: We Benchmarked Both (4x Speedup)
Free-threaded Python 3.14t hits 4x speedup on 4 threads — closing the gap to just 3.4x of Rust. We ran head-to-head CPU-bound benchmarks with full code. Here are the results.