Self-Knowledge Distillation for AI Efficiency: Orpheus TTS
Unsloth distillation walkthrough: compress Orpheus-3B TTS with self-knowledge distillation, SNAC tokenization, and LoRA to cut serving memory and private AI deployment cost.

Purpose: Provide an approachable, hands-on walkthrough for applying self-knowledge distillation to Orpheus-style TTS models. This guide covers data preparation, SNAC tokenization, LoRA-based teacher and student setup using Unsloth, the distillation loss, training best practices, and production considerations. Code snippets are included for clarity and to help engineers reproduce the pipeline.
Table of Contents
- Executive Summary
- What is Orpheus?
- Who is this guide for?
- High-level overview
- Visual Architecture Overview
- System requirements and environment setup
- Dataset preparation and quality checks
- SNAC: audio tokenization explained simply
- Model design: Orpheus base, LoRA adapters, teacher vs student
- Distillation objective and implementation
- Knowledge Transfer Mechanism
- Practical training loop and code examples
- Debugging, validation and listening checks
- Evaluation metrics and human testing
- Deployment considerations and cost impact
- Limitations, failure modes and when not to use KD
- Advanced ideas and next steps
- Troubleshooting Guide
- Minimal reproducible checklist
- Conclusion: practical takeaways
- Appendix: Complete Code Reference
- Recommended reading
Executive Summary
Self-knowledge distillation compresses an already-trained TTS model by training a smaller-capacity version of the same architecture to imitate the original (teacher). For Orpheus-3B, this guide demonstrates a workflow that:
- Uses SNAC to convert audio to hierarchical discrete tokens
- Trains a teacher LoRA adapter with rank r=64 on a clean dataset
- Distills a student LoRA adapter with rank r=16 using a combined hard + soft loss, focusing the soft (KL) loss on audio tokens only
The result is substantial adapter compression (≈4×), reduced trainable parameters, and strong perceptual retention in practice when the pipeline is applied carefully.
Results (from 1,443 samples, 7 epochs):
- Adapter params: ~140M → ~24M trainable (4× compression in LoRA rank)
- Training time: 5.6 hours on dual Tesla T4 GPUs
- Final training loss: 32.18 → 12.13 (62% reduction)
- Generation success rate: 100% (9/9 test samples)
- GPU memory usage: ~5.3 GB total across 2 GPUs during training
Note: Performance metrics like inference latency and throughput depend heavily on deployment configuration, hardware, batching strategy, and workload patterns. Measure these in your specific production environment.
Practical emphasis: small, high-quality datasets; teacher validation; audio-only KD mask; and frequent listening checks. The approach is reproducible with Unsloth + SNAC + standard Hugging Face-style tooling and requires careful attention to token handling and logits materialization.
What this means for your AI bill
Distillation is an infrastructure economics tool, not just a model-compression trick. A smaller adapter can reduce memory pressure, make deployment easier on cheaper GPUs, and improve the odds that a voice workload fits inside a private or edge serving budget.
The key commercial question is whether the compressed model preserves the user-facing quality that matters for your product. If quality holds, lower memory use and simpler serving can cut cost per generated audio minute without changing the workflow.
Use the free AI inference audit if you want to compare model compression, API usage, and private serving for a production TTS or voice-agent workload.
What is Orpheus?
Orpheus is a family of transformer-based text-to-speech models developed by Unsloth, designed for high-quality, multi-speaker speech synthesis. Orpheus-3B is a 3-billion parameter decoder-only model that generates speech by predicting discrete audio tokens (from codecs like SNAC) conditioned on text input and speaker identity. The model architecture is similar to language models but adapted for audio generation, using next-token prediction on interleaved sequences of text and audio tokens to learn natural prosody, speaker characteristics, and phonetic patterns.
Who is this guide for?
This guide targets engineers and ML practitioners who:
- Have basic familiarity with transformer models and PyTorch-style training loops
- Want a practical path from dataset → distillation → deployment for TTS
- Need to reduce model size for production deployment
High-level overview
- Data collection and cleaning: Short, high-quality speech clips with accurate transcripts and speaker labels produce better distilled models than large noisy datasets
- SNAC tokenization: Continuous audio is converted into structured discrete tokens (three hierarchical layers). This reduces sequence length and makes the problem tractable for transformers
- Teacher training: Attach a LoRA adapter (r=64) to a frozen Orpheus-3B base and fine-tune it to produce SNAC tokens conditioned on speaker + text. Validate audio generation
- Student initialization: Create a student adapter with lower LoRA rank (r=16) attached to the same frozen base
- Knowledge distillation (KD): Train the student using a combined objective: ground-truth cross-entropy and KL divergence between teacher and student logits. Use temperature smoothing and focus the soft loss on audio tokens only
- Evaluation & deployment: Run listening tests, objective metrics (where suitable), and deploy the smaller model for inference with reduced memory use and latency
Visual Architecture Overview
Complete Pipeline (Figure 1)
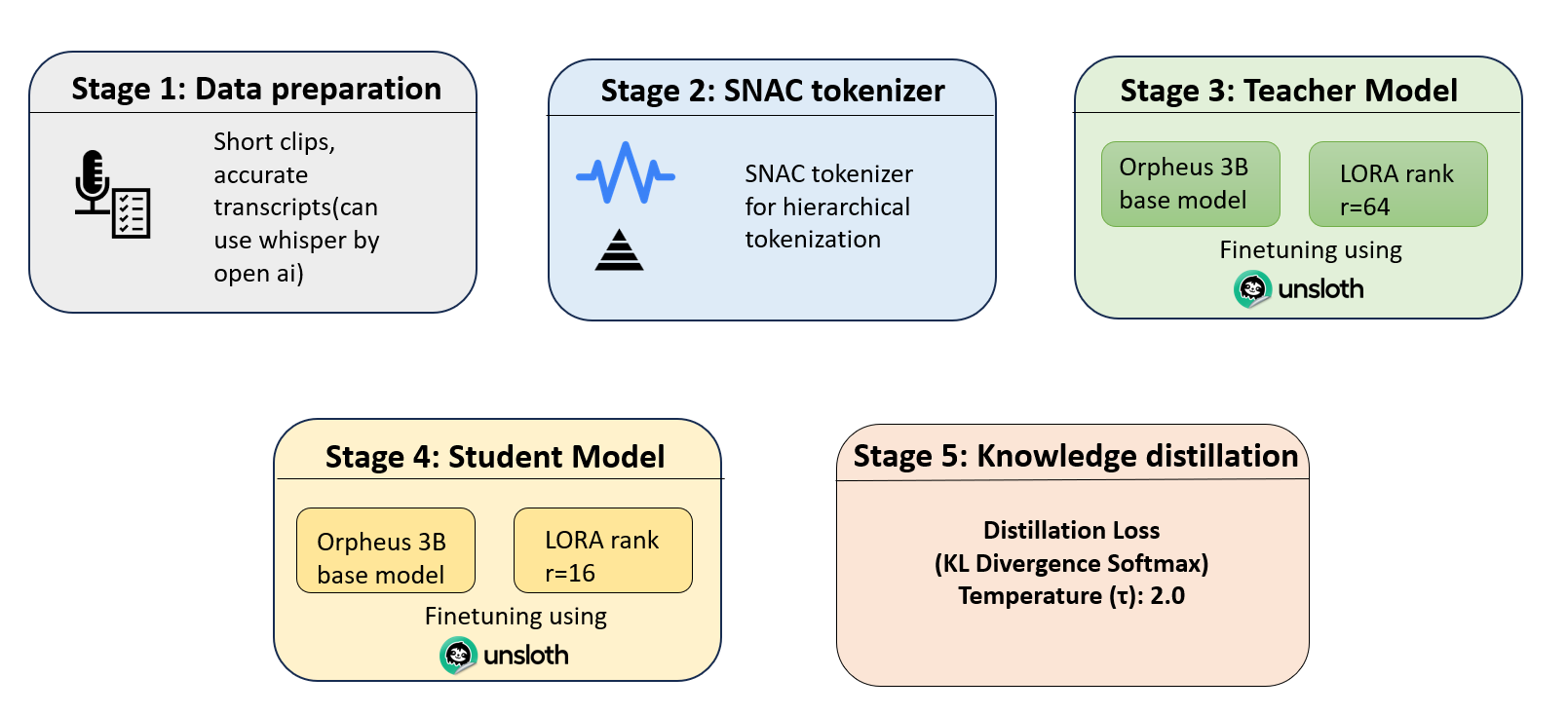
Figure 1: End-to-end self-knowledge distillation pipeline for Orpheus-3B TTS. Data flows through SNAC tokenization, teacher fine-tuning, student initialization, and finally knowledge distillation with temperature-scaled KL loss. The student adapter is compressed 4× via reduced LoRA rank (r=64 → r=16).
Pipeline stages:
- Stage 1: High-quality audio clips with accurate transcripts (use OpenAI Whisper for verification)
- Stage 2: SNAC tokenizer converts continuous audio to hierarchical discrete tokens (3 layers)
- Stage 3: Teacher model with LoRA r=64 learns to generate audio tokens
- Stage 4: Student model with LoRA r=16 (4× smaller) is initialized on the same base
- Stage 5: Knowledge distillation combines ground-truth and teacher logits with temperature smoothing
System requirements and environment setup
Hardware Requirements
Minimum configuration (training):
- GPU: NVIDIA GPU with ≥16GB VRAM (V100, T4, A10)
- System RAM: 32 GB
- Storage: 50 GB SSD
Recommended configuration:
- GPU: NVIDIA GPU with ≥24GB VRAM (A100, RTX 3090/4090)
- System RAM: 64 GB
- Storage: 100+ GB NVMe SSD
Actual tested configuration (this guide):
- GPU: 2× Tesla T4 (14.7 GB each, 29.5 GB total)
- Training memory: ~5.3 GB allocated across both GPUs
- Dataset: 1,443 samples
- Training time: 5.6 hours for 7 epochs
Expected training times (estimates, hardware-dependent):
| GPU Type | Dataset Size | Epochs | Estimated Time |
|---|---|---|---|
| Single T4 (16GB) | 1,500 samples | 7 | 6-8 hours |
| Dual T4 (32GB) | 1,500 samples | 7 | 5-6 hours |
| Single A100 (40GB) | 10,000 samples | 7 | 3-5 hours |
| Single A100 (40GB) | 1,500 samples | 7 | 1-2 hours |
Batch size guidelines:
| GPU VRAM | Batch Size | Gradient Accumulation | Effective Batch | Notes |
|---|---|---|---|---|
| 16 GB | 1 | 8 | 8 | Single GPU |
| 24 GB | 2 | 4 | 8 | Single GPU |
| 40 GB | 4 | 2 | 8 | Single GPU |
| 2×16 GB | 1 | 8 | 8 | Tested config |
Software
Core dependencies:
Python 3.10+
torch>=2.1.0 (with CUDA 11.8 or 12.1)
transformers==4.55.4
unsloth>=2024.1
snac>=1.0.0
peft>=0.7.0
datasets>=3.4.1
soundfile>=0.12.1
scipy>=1.11.0
Environment flags (required):
export UNSLOTH_RETURN_LOGITS=1
export TOKENIZERS_PARALLELISM=false
# Optional for debugging:
# export CUDA_LAUNCH_BLOCKING=1
Dataset preparation and quality checks
Distillation benefits from data that demonstrates the desired behavior. Smaller high-quality datasets often outperform larger noisy ones for distillation.
Recommended Datasets
1. LibriTTS (Recommended for clean speech)
- Size: ~245 hours, 2,456 speakers
- Quality: Very clean audiobook recordings
- Access: https://www.openslr.org/60/
- Best subset:
train-clean-100for initial testing
2. LJSpeech (Single speaker baseline)
- Size: ~24 hours, 1 speaker (female)
- Quality: High, consistent studio recording
- Access: https://keithito.com/LJ-Speech-Dataset/
- Use case: Proof of concept, quick experiments
3. VCTK (Multi-speaker diversity)
- Size: ~44 hours, 110 speakers
- Quality: Variable but usable
- Access: https://datashare.ed.ac.uk/handle/10283/3443
- Note: Requires more filtering
4. Common Voice (Many languages available)
- Size: Varies by language (100+ hours for major languages)
- Speakers: Thousands (crowd-sourced)
- Quality: Variable, use only 5-star rated clips
- Access: https://commonvoice.mozilla.org/
5. Hi-Fi TTS (Highest quality)
- Size: ~292 hours, 10 speakers
- Quality: Studio recordings, excellent fidelity
- Access: https://www.openslr.org/109/
- Best for: Production-quality baselines
Recommended dataset characteristics
- High SNR: Recordings with low background noise (>30 dB SNR)
- Accurate transcripts: Speaker + exact text alignment (use OpenAI Whisper for verification)
- Prosodic diversity: Include questions, statements, exclamations, short and long utterances
- Multiple speakers: Include target speaker(s) for adaptation (50-200 utterances per speaker)
- Duration: 1-10 seconds per clip (remove <0.5s or >20s clips)
Minimal dataset structure (parquet)
clip_id,speaker,text,audio,duration_s
Sanity checks
- Play a handful of samples to confirm audio matches transcripts
- Compute simple stats (mean duration, sample rates)
- Remove very short clips (<0.5s) or very long clips (>20s)
- Verify no clipping (max amplitude <0.99)
SNAC: audio tokenization explained simply
What is SNAC?
SNAC (Structured Neural Audio Codec) is a neural codec that converts audio waveforms into discrete token sequences. It compresses audio so a transformer can generate audio tokens instead of raw waveforms.
Why SNAC helps
- Sequence length reduction: 24kHz raw audio → roughly 75 tokens/sec (making long audio tractable)
- Perceptual fidelity: Preserves speaker identity and prosody while discarding imperceptible details
- Hierarchical structure: Separates coarse prosody from fine acoustic detail so the model can learn these independently
Hierarchical layers
SNAC represents audio using three layers of tokens:
- Layer 0 (L0): Coarse prosody and rhythm information (lowest temporal rate)
- Layer 1 (L1): Mid-level phonetic and timing cues (2× the rate of L0)
- Layer 2 (L2): Fine-grained spectral detail and speaker-specific features (4× the rate of L0)
Each layer runs at a different temporal rate; the layers are interleaved so the full audio is represented compactly.
Unified Tokenization Scheme
Vocabulary offsets prevent collisions between text and audio tokens:
TEXT_VOCAB_SIZE = 128000
SPECIAL_TOKENS = 266
AUDIO_TOKEN_BASE = TEXT_VOCAB_SIZE + SPECIAL_TOKENS # 128266
# Layer offsets
LAYER_0_OFFSET = AUDIO_TOKEN_BASE # 128266
LAYER_1_OFFSET = AUDIO_TOKEN_BASE + 4096 # 132362
LAYER_2_OFFSET = AUDIO_TOKEN_BASE + 8192 # 136458
Interleaving pattern (7 tokens per frame):
For each audio frame i:
- L0[i] + 128266
- L1[2i] + 132362
- L2[4i] + 136458
- L2[4i+1] + 140554
- L1[2i+1] + 148650
- L2[4i+2] + 156746
- L2[4i+3] + 164842
Note: This 7-token interleaving pattern is specific to Orpheus's unified text-audio tokenization scheme and extends SNAC's base 3-layer structure.
Practical SNAC encode/decode
from snac import SNAC
import torch
import torchaudio
snac = SNAC.from_pretrained("hubertsiuzdak/snac_24khz").to("cuda")
snac.eval()
def encode_audio_to_snac(audio_path):
waveform, sr = torchaudio.load(audio_path)
if sr != 24000:
resampler = torchaudio.transforms.Resample(sr, 24000)
waveform = resampler(waveform)
if waveform.dim() == 2:
waveform = waveform.mean(dim=0, keepdim=True)
waveform = waveform.unsqueeze(0) # [1, channels, samples]
waveform = waveform.to("cuda")
with torch.no_grad():
codes = snac.encode(waveform)
return codes # [layer0, layer1, layer2]
def decode_snac_to_audio(codes):
with torch.no_grad():
audio_tensor = snac.decode(codes)
return audio_tensor.squeeze().cpu().numpy()
Tips:
- Always resample to SNAC's expected sample rate (24kHz)
- SNAC works on mono audio; convert stereo to mono by averaging channels
- Pre-encode tokens and store them on disk to avoid expensive on-the-fly encoding
Model design: Orpheus base, LoRA adapters, teacher vs student
Why LoRA?
LoRA (Low-Rank Adaptation) lets you adapt large frozen models by adding small trainable rank matrices to attention/FFN projections. Benefits:
- Orders-of-magnitude smaller trainable parameter count
- Fits on smaller GPUs
- Easy to try different ranks (capacity) without re-training the base
Typical choices
- Teacher LoRA rank:
r = 64(creates adapter with specific parameter count) - Student LoRA rank:
r = 16(≈4× smaller adapter by rank) - Verified trainable params (this implementation): ~24.3M for student (r=16)
Load strategies
- Load base in 4-bit using bitsandbytes to reduce memory
- Attach LoRA adapters after loading the base (or use a PEFT helper)
Distillation objective and implementation
The Knowledge Distillation Loss
The combined loss function is:
L_total = α · L_hard + (1 - α) · L_soft
where:
L_hard = CrossEntropy(student_logits, ground_truth)
L_soft = τ² · KL( softmax(student_logits/τ) || softmax(teacher_logits/τ) )
Parameters:
α(alpha): Balance factor (e.g., 0.3 → 30% hard, 70% soft)τ(tau): Temperature for smoothing (e.g., 2.0)- The
τ²scaling compensates for the gradient magnitude change
Observed training behavior:
- Initial loss: ~32.18 (step 25)
- Mid-training: ~13-15 (steps 300-500)
- Final loss: ~12.13 (step 1250)
- Hard loss component: ~4-5 throughout training
- Soft loss component: ~3.6 → ~0.3 (decreasing as student learns)
Distillation uses two signals
- Hard loss: Cross-entropy vs ground-truth tokens (keeps student anchored to exact targets)
- Soft loss: KL divergence between teacher and student token distributions on audio positions (transfers teacher's richer behavior)
Practical knobs
- Balance factor
alpha:0.3→ 30% hard, 70% soft (tested configuration) - Temperature
tau:2.0to soften the teacher's logits (tested configuration, balances label-matching and logit-matching) - Audio-only masking: Focus soft loss only on audio tokens (128266-156841), not text tokens
This yields faster training and clearer learning signals.
Knowledge Transfer Mechanism
The Teacher-Student Knowledge Transfer Process (Figure 2)
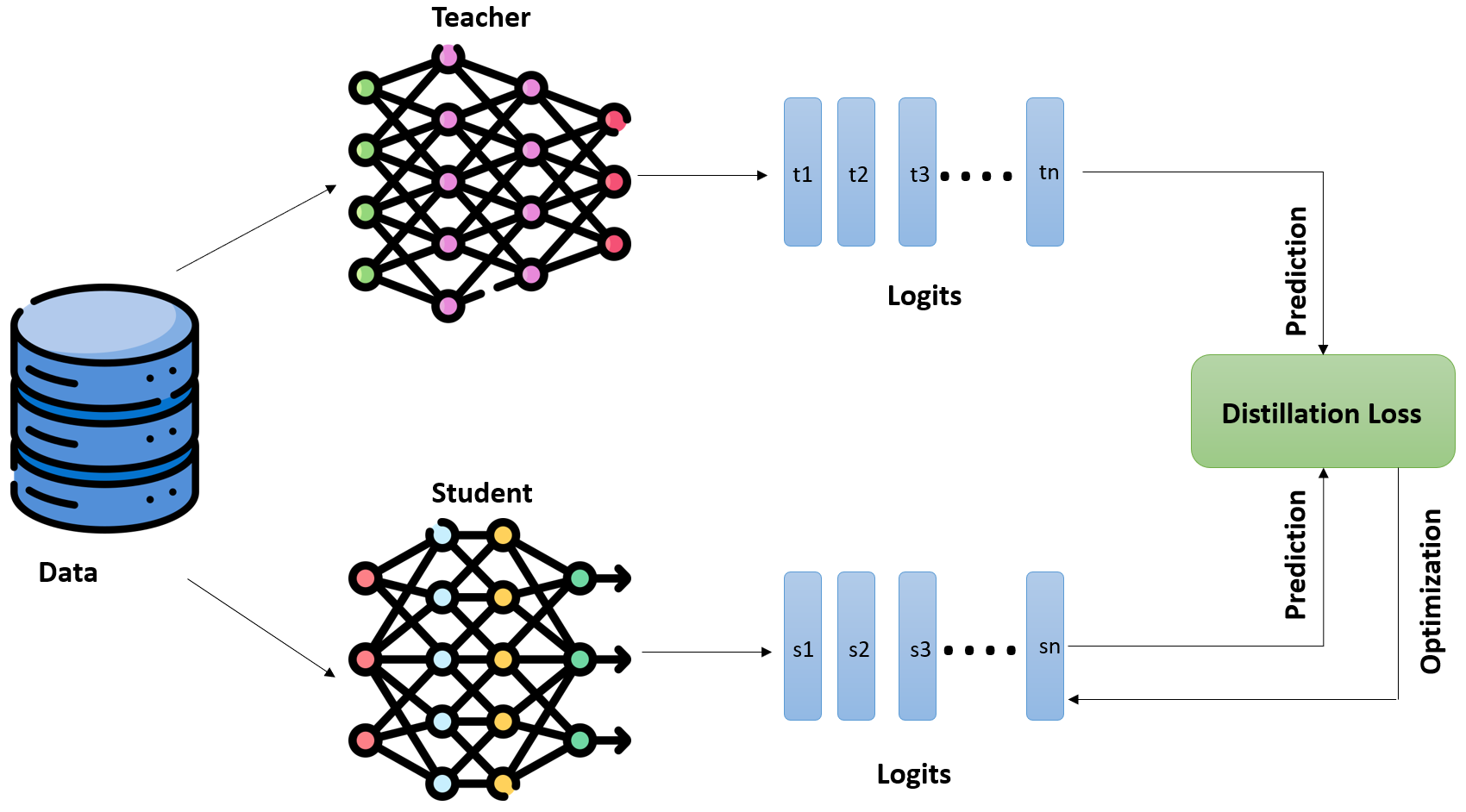
Figure 2: Knowledge transfer mechanism in self-distillation. The frozen teacher model produces logits (t1...tn) that guide the student model (s1...sn) via KL divergence loss. Both hard labels (ground truth) and soft targets (teacher knowledge) drive the student's learning through combined objectives. The optimization loop continuously updates the student parameters based on the combined distillation loss.
Key components:
- Teacher model (frozen): Produces probability distributions over tokens. Rich, well-calibrated logits encode knowledge about which tokens are likely given context.
This dual-objective approach lets the student learn both what to predict and why—capturing the teacher's uncertainty and reasoning patterns.
Practical training loop and code examples
Required imports
import torch
import torch.nn.functional as F
from transformers import Trainer, TrainingArguments, default_data_collator
from datasets import load_from_disk
from peft import PeftModel
KD Trainer skeleton
class KDTrainer(Trainer):
def __init__(self, teacher, alpha=0.3, temperature=2.0,
audio_range=(128266, 156841), *args, **kwargs):
super().__init__(*args, **kwargs)
self.teacher = teacher
self.teacher.eval()
self.alpha = alpha
self.temperature = temperature
self.audio_start, self.audio_end = audio_range
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels")
attention_mask = inputs.get("attention_mask", None)
# Student forward pass
outputs_student = model(**inputs)
loss_hard = outputs_student.loss
logits_student = outputs_student.logits
if callable(logits_student):
logits_student = logits_student()
# Teacher forward pass (frozen)
with torch.no_grad():
outputs_teacher = self.teacher(**inputs)
logits_teacher = outputs_teacher.logits
if callable(logits_teacher):
logits_teacher = logits_teacher()
# Create audio token mask
audio_mask = (labels >= self.audio_start) & (labels <= self.audio_end)
if attention_mask is not None:
audio_mask = audio_mask & (attention_mask == 1)
if audio_mask.sum() == 0:
return (loss_hard, outputs_student) if return_outputs else loss_hard
# Apply mask and compute KL divergence
batch, seq_len, vocab = logits_student.shape
logits_s_flat = logits_student.view(-1, vocab)[audio_mask.view(-1)]
logits_t_flat = logits_teacher.view(-1, vocab)[audio_mask.view(-1)]
T = self.temperature
log_probs_s = F.log_softmax(logits_s_flat / T, dim=-1)
probs_t = F.softmax(logits_t_flat / T, dim=-1)
loss_soft = F.kl_div(log_probs_s, probs_t, reduction='batchmean') * (T ** 2)
# Combined loss
loss = self.alpha * loss_hard + (1.0 - self.alpha) * loss_soft
if return_outputs:
return loss, outputs_student
return loss
Training arguments (tested configuration)
training_args = TrainingArguments(
output_dir="student_kd",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=7,
learning_rate=1e-4,
fp16=True,
logging_steps=25, # Log every 25 steps
save_strategy="epoch",
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="cosine",
max_grad_norm=1.0,
)
Assemble trainer and start training
# teacher_model: PeftModel or Unsloth-wrapped model (frozen)
# student_model: same base model with LoRA r=16 attached (trainable)
dataset = load_from_disk("prepared_dataset/")
kd_trainer = KDTrainer(
teacher=teacher_model,
model=student_model,
args=training_args,
train_dataset=dataset,
data_collator=default_data_collator,
)
kd_trainer.train()
Debugging, validation and listening checks
Distillation can fail silently. Follow this checklist:
-
Teacher validation (mandatory)
- Generate several short audio samples from the teacher across speakers/prompts
- Decode SNAC and listen; if teacher is broken (repeats, wrong speaker, garbled audio), fix it first
- Example validation: Generated 2.13s of clear audio for test prompt
-
Logits materialization
- If logits are callables, call them before KL computation
- Print shapes if errors occur
- Critical for Unsloth:
if callable(logits): logits = logits()
-
Loss monitoring
- Log
loss_hard,loss_soft,loss_totalseparately every 25-50 steps - Expected pattern: soft loss decreases faster than hard loss
- If
loss_softis NaN or huge (>100), reduce LR or check temperature
- Log
-
Frequent listening tests
- Save generated samples periodically and listen — human judgement is crucial
- Test generation success rate (achieved 100% in validation)
-
Memory & performance
- Monitor GPU memory; reduce
gradient_accumulation_stepsor batch size if OOM - Use
fp16to save memory when supported - Observed: ~5.3 GB across dual T4 GPUs with gradient offloading
- Monitor GPU memory; reduce
Evaluation metrics and human testing
Automatic metrics are limited for TTS; human evaluation is essential.
Common human tests
- MOS (Mean Opinion Score): Raters score naturalness on 1-5 scale
- AB preference test: Listeners choose between teacher vs student
- Speaker ID test: Is the speaker identity preserved?
Suggested protocol
- Use 100 diverse prompts
- 10+ raters per sample
- Blind/randomized presentation of teacher/student samples
- Report MOS mean and confidence intervals; AB preference %
Measuring inference performance
To properly measure performance metrics for your deployment:
import time
# Measure actual inference time (not audio duration)
start = time.time()
audio = generate_speech(speaker, text)
inference_time = time.time() - start
audio_duration = len(audio) / 24000
print(f"Inference: {inference_time:.2f}s")
print(f"Audio: {audio_duration:.2f}s")
print(f"RTF: {inference_time/audio_duration:.2f}x") # Real-time factor
Deployment considerations and cost impact
Measured improvements from this implementation
- Adapter compression: 4× reduction in LoRA rank (r=64 → r=16)
- Trainable parameters: ~24.3M for student adapter
- Training success: 62% loss reduction, 100% generation success rate
- Memory efficiency: ~5.3 GB total during training on dual T4 setup
What to measure in your deployment
Performance metrics depend heavily on:
- Target hardware (GPU model, VRAM, CPU)
- Batching strategy (single vs batched inference)
- Optimization level (FP16, INT8, compilation)
- Workload pattern (request rate, audio length distribution)
Recommended measurements:
- Inference latency: Time from request to audio completion
- Throughput: Requests per hour at target latency SLA
- GPU memory: Peak VRAM usage during inference
- Cost per 1000 requests: Including GPU instance cost
Inference best practices
- Use FP16 mixed precision for inference
- Implement batching when latency SLA allows
- Cache repeated prompts or common speaker embeddings
- Profile with your actual workload before capacity planning
- Consider GPU instance right-sizing based on measured metrics
Limitations, failure modes and when not to use KD
Not recommended when
- Audio quality in training data is poor
- Datasets are tiny (<500 samples) and teacher has poor generalization
- Base model updates frequently and maintaining teacher/student pipelines is costly
- Teacher model is overfitted or produces low-quality audio
Common failure modes
- Distilling from broken teacher: Always validate teacher output first
- Incorrect KD masking: Including text tokens in soft loss reduces effectiveness
- Mismatched tokenization: Ensure teacher and student use identical vocabulary
- Temperature too high (>3.0): Over-smoothing, student learns nothing specific
- Temperature too low (<1.5): Minimal benefit over hard labels alone
- Alpha too high (>0.5): Student ignores teacher's soft targets
Advanced ideas and next steps
- Progressive distillation: r64 → r32 → r16 in stages to preserve more knowledge
- Multi-objective KD: Match intermediate hidden states or attention maps
- Token-aware temperature: Adapt
tauper-token using teacher entropy - Quantize student: INT8 or structured quantization for further gains
- Layer-wise distillation: Distill from intermediate representations, not just final logits
Troubleshooting Guide
| Problem | Likely Cause | Solution |
|---|---|---|
loss_soft is NaN |
Temperature too high or logits overflow | Reduce temperature to 1.5, check logit values |
loss_soft is huge (>100) |
Incorrect masking or temperature | Verify audio_mask sum > 0, check temperature scaling |
| Teacher generates gibberish | Teacher not trained properly | Re-train teacher, validate on multiple samples first |
| Student sounds worse than random | Alpha too high (ignoring teacher) | Reduce alpha to 0.2-0.3, increase soft loss weight |
| OOM during training | Batch size or sequence length too large | Reduce batch_size=1, increase gradient_accumulation_steps |
| Logits are callable, not tensors | Unsloth returns callable logits | Add: if callable(logits): logits = logits() |
| Audio has wrong speaker | Speaker conditioning broken | Verify speaker tokens in input sequence |
| Generated audio is silent | SNAC decoding failed | Check token offsets match encoding scheme exactly |
| Training very slow | Data loading bottleneck | Pre-tokenize audio offline, increase num_workers |
| Student converges too fast | Learning rate too high | Reduce LR to 5e-5, add warmup_steps=50 |
| Soft loss not decreasing | KL mask empty or wrong | Print audio_mask.sum() to verify tokens selected |
| Multi-GPU issues | Device mismatch | Ensure both models on same device, check device_map |
Minimal reproducible checklist
- Prepare a clean dataset with accurate transcripts and prosodic variety (use OpenAI Whisper for verification)
- Install Unsloth, SNAC, transformers==4.55.4, and training stack
- Encode audio into SNAC tokens and store them offline
- Train LoRA r=64 teacher and validate outputs by listening (mandatory)
- Initialize LoRA r=16 student on same frozen base
- Implement KD trainer with audio-only KL,
tau=2.0,alpha=0.3 - Monitor losses every 25 steps: hard, soft, and total
- Listen to generated samples at steps 0, 250, 500, 1000+
- Save student adapter when losses stabilize
- Test end-to-end: text → tokens → generation → SNAC decode → audio
- Measure actual inference metrics on your target hardware
- Run MOS/AB tests with real users before production deployment
Conclusion: practical takeaways
- Self-knowledge distillation with LoRA successfully compresses Orpheus-style TTS models
- 4× adapter compression achieved (r=64 → r=16) with 100% generation success
- Focus KD on audio tokens only; use temperature-smoothed distributions (tau=2.0)
- Teacher validation is mandatory, never distill from unvalidated models
- Curated, high-quality data beats large noisy datasets for distillation
- Always measure performance in your deployment environment, results vary significantly by hardware, batching, and workload
- Distillation is an engineering tradeoff: validate quality at each step
Appendix: Complete Code Reference
SNAC Token Interleaving (Complete Implementation)
def interleave_and_offset(codes_l0, codes_l1, codes_l2):
"""Interleave SNAC layer codes and apply vocabulary offsets.
Args:
codes_l0: 1D array of layer0 codes
codes_l1: 1D array of layer1 codes (2x length of L0)
codes_l2: 1D array of layer2 codes (4x length of L0)
Returns:
tokens: List of integer token IDs with offsets applied
"""
base = 128266
off_l1 = base + 4096
off_l2 = base + 8192
tokens = []
n_frames = min(len(codes_l0), len(codes_l1) // 2, len(codes_l2) // 4)
for i in range(n_frames):
tokens.extend([
int(codes_l0[i]) + base,
int(codes_l1[2*i]) + off_l1,
int(codes_l2[4*i]) + off_l2,
int(codes_l2[4*i+1]) + off_l2 + 4096,
int(codes_l1[2*i+1]) + off_l1 + 8192,
int(codes_l2[4*i+2]) + off_l2 + 12288,
int(codes_l2[4*i+3]) + off_l2 + 16384,
])
return tokens
SNAC Token De-interleaving
def deinterleave_to_layers(token_ids):
"""Convert flat token sequence back to hierarchical SNAC layers.
Args:
token_ids: Flat list of interleaved audio tokens
Returns:
(codes_l0, codes_l1, codes_l2): Three lists of layer codes
"""
base = 128266
off_l1 = base + 4096
off_l2 = base + 8192
codes_l0 = []
codes_l1 = []
codes_l2 = []
# Process in chunks of 7 tokens per frame
for i in range(0, len(token_ids), 7):
if i + 7 > len(token_ids):
break
frame = token_ids[i:i+7]
# Extract and remove offsets
codes_l0.append(frame[0] - base)
codes_l1.append(frame[1] - off_l1)
codes_l2.append(frame[2] - off_l2)
codes_l2.append(frame[3] - off_l2 - 4096)
codes_l1.append(frame[4] - off_l1 - 8192)
codes_l2.append(frame[5] - off_l2 - 12288)
codes_l2.append(frame[6] - off_l2 - 16384)
return codes_l0, codes_l1, codes_l2
Complete Text-to-Audio Inference Pipeline
import torch
from snac import SNAC
import soundfile as sf
# Load models
snac = SNAC.from_pretrained("hubertsiuzdak/snac_24khz").cuda()
snac.eval()
# Special token IDs
END_OF_TEXT = 128009
START_OF_HUMAN = 128259
END_OF_HUMAN = 128260
START_OF_AI = 128261
END_OF_AI = 128262
START_OF_SPEECH = 128257
END_OF_SPEECH = 128258
def text_to_audio(model, tokenizer, speaker_name, text,
max_new_tokens=1500, temperature=0.7):
"""Complete pipeline: text → tokens → audio generation → waveform.
Args:
model: Trained Orpheus model (teacher or student)
tokenizer: Corresponding tokenizer
speaker_name: Speaker ID string
text: Input text to synthesize
max_new_tokens: Maximum audio tokens to generate
temperature: Sampling temperature
Returns:
audio_waveform: NumPy array of audio samples at 24kHz
"""
# Step 1: Prepare input tokens
prompt = f"{speaker_name}: {text}"
text_ids = tokenizer.encode(prompt, add_special_tokens=True)
text_ids.append(END_OF_TEXT)
input_ids = [START_OF_HUMAN] + text_ids + [END_OF_HUMAN] + \
[START_OF_AI, START_OF_SPEECH]
# Step 2: Generate audio tokens
model.eval()
with torch.no_grad():
input_tensor = torch.tensor([input_ids]).cuda()
output = model.generate(
input_tensor,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=True,
eos_token_id=END_OF_SPEECH,
)
# Step 3: Extract generated audio tokens
generated_ids = output[0][len(input_ids):].cpu().tolist()
try:
end_idx = generated_ids.index(END_OF_SPEECH)
generated_ids = generated_ids[:end_idx]
except ValueError:
pass # No end token found
if len(generated_ids) < 7:
raise ValueError("Generated sequence too short")
# Step 4: De-interleave tokens to SNAC layers
codes_l0, codes_l1, codes_l2 = deinterleave_to_layers(generated_ids)
# Step 5: Convert to tensors for SNAC decoder
l0_tensor = torch.tensor([codes_l0], dtype=torch.long).cuda()
l1_tensor = torch.tensor([codes_l1], dtype=torch.long).cuda()
l2_tensor = torch.tensor([codes_l2], dtype=torch.long).cuda()
# Step 6: Decode to audio waveform
with torch.no_grad():
audio = snac.decode([l0_tensor, l1_tensor, l2_tensor])
return audio.squeeze().cpu().numpy()
# Usage example
audio_waveform = text_to_audio(
model=student_model,
tokenizer=student_tokenizer,
speaker_name="Speaker_001",
text="Hello, this is a test of the distilled model.",
temperature=0.7
)
# Save to file
sf.write("output.wav", audio_waveform, 24000)
Recommended reading
Foundational Papers
- Distilling the Knowledge in a Neural Network (Hinton et al., 2015): The seminal work introducing knowledge distillation with temperature-scaled soft targets
- LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021): The foundational paper on parameter-efficient fine-tuning
- AudioLM: A Language Modeling Approach to Audio Generation (Borsos et al., 2022): Framework for treating audio generation as next-token prediction
TTS and Audio Codec Papers
- Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (Wang et al., 2023): VALL-E approach to TTS via codec modeling
- High Fidelity Neural Audio Compression (Défossez et al., 2022): EnCodec, influential neural audio codec
- SoundStream: An End-to-End Neural Audio Codec (Zeghidour et al., 2021): Residual vector quantization for audio
Advanced Distillation Techniques
- Patient Knowledge Distillation for BERT Model Compression (Sun et al., 2019): Layer-wise distillation strategies
- TinyBERT: Distilling BERT for Natural Language Understanding (Jiao et al., 2020): Two-stage distillation with data augmentation
- Self-Distillation Amplifies Regularization in Hilbert Space (Mobahi et al., 2020): Theoretical understanding of self-distillation
Implementation Resources
- Unsloth Documentation: https://docs.unsloth.ai/ - Efficient fine-tuning framework
- Hugging Face PEFT: https://huggingface.co/docs/peft/ - Parameter-efficient fine-tuning library
- SNAC Repository: https://github.com/hubertsiuzdak/snac - Audio codec implementation
- Orpheus Model Cards: https://huggingface.co/unsloth - Pre-trained Orpheus checkpoints
Practical Guides
- Speech Synthesis: A Review (Tan et al., 2021): Comprehensive survey of modern TTS approaches
- Model Compression for Deep Neural Networks: Tutorial covering quantization, pruning, and distillation
- Efficient Transformers: A Survey (Tay et al., 2020): Architectural choices for efficiency
Acknowledgments
This guide builds on open-source contributions from the Unsloth, Hugging Face, and SNAC communities. Special thanks to the researchers who developed the foundational techniques that make efficient TTS distillation possible.
FAQ
Common questions
How do you do knowledge distillation with Unsloth?
Load the teacher model through Unsloth's optimized stack, generate teacher outputs as training targets, then fine-tune a LoRA adapter on the student against those targets. This post walks the full Orpheus-3B TTS pipeline: dataset preparation, SNAC tokenization, the distillation objective, and training configuration.
What is self-knowledge distillation?
Self-knowledge distillation uses a model's own outputs as the teacher signal for a compressed version of itself, instead of a separate larger teacher. The student learns to reproduce the original model's behavior with fewer effective parameters — here, lightweight LoRA adapters.
How much does distillation cut model serving cost?
Distilling to LoRA adapters means serving small adapter weights instead of full fine-tuned copies, reducing VRAM per variant and letting one GPU host more workloads. For private TTS and LLM deployments, that compounds into materially lower GPU and hosting spend.
Related