OatRAG on Jetson Orin Nano: Enterprise RAG in Under 100MB
We ran a full RAG stack on an NVIDIA Jetson Orin Nano in 90 MB — an 84.8% memory cut vs a traditional stack, leaving 6.45 GB free for the LLM.
Most RAG systems focus on optimizing models. We focused on optimizing everything around the model.
During our testing, a traditional RAG stack consumed nearly 600 MB of runtime memory before inference even began.
OatRAG reduced that footprint to just 90.36 MB.
That's an 84.8% reduction in infrastructure memory usage, leaving more resources available for language models, embeddings, context windows, and concurrent users.
This is the story of how we built a production-grade RAG platform that consumes less memory than many standalone web applications.
The Headline Result
| Metric | Value |
|---|---|
| Total Jetson Memory | 7.6 GB |
| Memory Used by OatRAG Stack | 90.36 MB |
| Total System RAM Usage | 917 MB |
| Available Memory for Models | 6.45 GB |
| Available Memory Percentage | 84.8% |
Key Finding
The complete OatRAG platform—including backend APIs, vector database, retrieval engine, analytics, and frontend delivery—consumed only 90.36 MB of RAM.
That leaves the overwhelming majority of Jetson memory available for running language models.
For edge AI deployments, this distinction matters. Infrastructure overhead should never become the bottleneck that limits model size, context length, or concurrent users.
Why This Matters
On Jetson Orin Nano, CPU and GPU share the same 8GB unified memory pool.
That memory must simultaneously hold:
- Operating system
- Application services
- Databases
- Model weights
- KV cache
- Runtime buffers
- Active inference workloads
Many AI applications consume hundreds of megabytes before inference even begins.
OatRAG was designed differently.
Instead of maximizing framework layers and runtime dependencies, the goal was to minimize overhead while maintaining enterprise-grade retrieval capabilities.
The result is a production-ready RAG platform that consumes less memory than many standalone API servers. If you're weighing edge or on-prem deployment against a managed API, the on-prem LLM cost estimator models the break-even.
Deployment Footprint
Before a single query is executed, infrastructure size matters.
Lightweight deployments reduce update times, improve portability, and leave more resources available for AI workloads.
The complete OatRAG deployment consists of only three lightweight application containers alongside Ollama.

Docker Image Sizes
| Container Image | Disk Size |
|---|---|
| oat-rag | 120 MB |
| Oat UI | 67.5 MB |
| pgvector/pgvector | 459 MB |
| ollama/ollama | 4.16 GB |
Key Observation
Excluding the inference runtime itself, the entire OatRAG application stack occupies less than 650 MB of storage.
This allows rapid deployment even in bandwidth-constrained environments and makes updates significantly easier than larger enterprise AI stacks.
Container-Level Memory Breakdown
One of the primary goals behind OatRAG was reducing infrastructure overhead to an absolute minimum.
The following measurements were captured directly from the live Jetson deployment.

OatRAG vs Traditional RAG Architectures
A common question we receive is:
Why build OatRAG in Rust when existing stacks already work?
To answer this, we compared OatRAG against a typical modern RAG deployment consisting of:
- Next.js Frontend
- Express Backend
- ChromaDB
- Python Runtime
- Ollama
This architecture is common across internal AI assistants, proof-of-concept RAG deployments, and many open-source projects.
The results highlight how infrastructure choices directly impact edge deployment efficiency. For a cost-and-control comparison of these approaches, see our guide on edge RAG vs the OpenAI API.
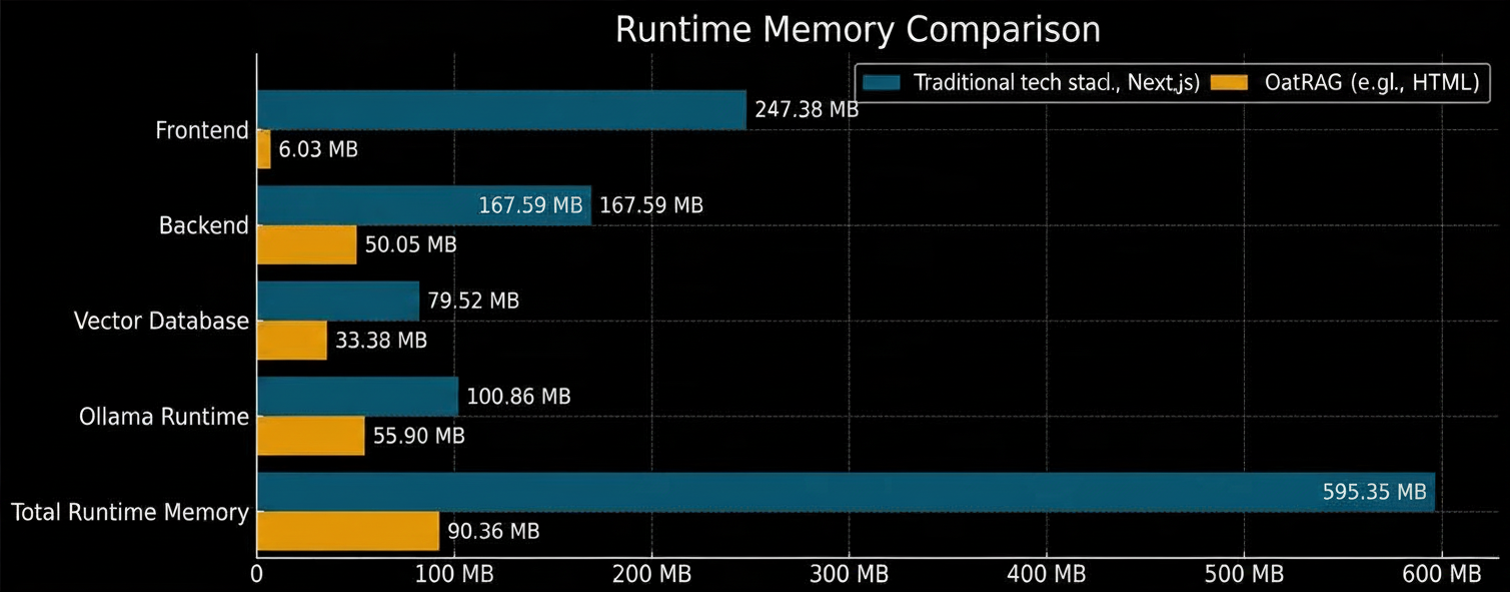
Runtime Memory Comparison
| Component | Traditional Stack | OatRAG |
|---|---|---|
| Frontend | 247.38 MB | 6.93 MB |
| Backend | 167.59 MB | 50.05 MB |
| Vector Database | 79.52 MB | 33.38 MB |
| Ollama Runtime | 100.86 MB | 55.90 MB |
| Total Runtime Memory | 595.35 MB | 90.36 MB |
Memory Reduction
| Metric | Value |
|---|---|
| Traditional Stack | 595.35 MB |
| OatRAG | 90.36 MB |
| Memory Saved | 504.99 MB |
| Reduction Percentage | 84.8% |
| Efficiency Improvement | 6.6× |
Key Finding
OatRAG reduces infrastructure memory consumption by nearly 85%, freeing more than 500 MB of additional RAM for language models, embeddings, KV cache, and concurrent users.
What Makes the Difference?
The memory savings do not come from using a smaller model.
They come from eliminating unnecessary infrastructure overhead.
| Traditional Approach | OatRAG Approach |
|---|---|
| Next.js Dev Server | Oat UI |
| Express + TSX Watchers | Rust + Axum |
| Python + ChromaDB | PostgreSQL + pgvector |
| Large Runtime Dependencies | Native Compiled Binaries |
| Multiple Runtime Layers | Single Lightweight Stack |
Instead of asking:
"How can we make the model smaller?"
We asked:
"How can we make everything around the model smaller?"
That philosophy ultimately resulted in over 500 MB of additional memory being available for inference on an 8GB Jetson Orin Nano.
Memory Consumption by Service
| Service | Memory Usage |
|---|---|
| PostgreSQL + pgvector | 33.38 MB |
| OatRAG Backend (Rust + Axum) | 50.05 MB |
| Oat Frontend | 6.93 MB |
| Total | 90.36 MB |
What Stands Out?
The complete platform remained below 100 MB even while serving live requests.
For comparison:
| Runtime | Typical Memory Usage |
|---|---|
| Node.js API Service | 150–250 MB |
| Python API Service | 150–300 MB |
| OatRAG Full Platform | 90 MB |
The entire OatRAG infrastructure stack consumes less memory than many standalone Python or Node.js services.
On an 8GB Jetson Orin Nano, that means more memory remains available for what actually matters: running language models.
The Secret: Rust Instead of Heavy Runtime Layers
One of the biggest contributors to OatRAG's efficiency is its backend architecture.
Rather than relying on interpreted runtimes, OatRAG uses a compiled Rust backend powered by Axum.
Why Rust Matters
Rust provides:
- No garbage collection pauses
- Minimal runtime overhead
- Predictable memory allocation
- High-performance asynchronous execution
- Native machine code performance
The entire backend—including retrieval orchestration, SSE streaming, analytics, and API serving—operates in just 51 MB of resident memory.
This is one of the primary reasons OatRAG maintains such a small operational footprint.
Retrieval Is Not the Bottleneck
A common misconception is that vector search dominates RAG latency.
Our measurements show the opposite.
Average Pipeline Latency
| Pipeline Stage | Average Time |
|---|---|
| Hybrid Retrieval | 127.5 ms |
| Context Compilation | 0.28 ms |
| Time-to-First-Token (TTFT) | 3,329 ms |
| Token Generation | 41,204 ms |
Key Observation
Retrieval contributes less than 1% of overall query time.
The overwhelming majority of latency originates from model inference itself.
This validates one of OatRAG's core design principles:
Retrieval should be fast enough that the language model remains the dominant contributor to latency.
Hybrid Search Architecture
Modern enterprise knowledge bases require more than vector search alone.
OatRAG combines three complementary retrieval strategies.
| Technique | Purpose |
|---|---|
| pgvector HNSW | Semantic Search |
| SQLite FTS5 BM25 | Keyword Search |
| Reciprocal Rank Fusion (RRF) | Result Fusion |
Instead of choosing between semantic search and keyword search, OatRAG uses both.
This hybrid approach improves:
- Recall
- Precision
- Citation quality
- Enterprise document retrieval accuracy
while maintaining sub-150ms retrieval times.
Chunk Structure
| Layer | Size | Purpose |
|---|---|---|
| Child Chunk | 100–200 Characters | Precise Retrieval |
| Parent Chunk | ~1000 Characters | Rich Context |
The retrieval engine searches small chunks but returns larger parent sections to the language model.
This architecture provides:
- Better retrieval accuracy
- More complete context
- Reduced hallucinations
- Improved answer quality
without increasing retrieval latency.
refer to our Jetson Orin Nano LLM Benchmark, which evaluates real-world inference performance under production workloads.
Memory-Aware Model Management
Large language models introduce another challenge on embedded devices.
Memory exhaustion.
To address this, OatRAG actively manages model lifecycles.
The platform:
- Monitors active Ollama sessions
- Detects idle models
- Automatically unloads inactive models
- Reclaims memory immediately after use
This proactive strategy helps prevent out-of-memory conditions while maintaining system responsiveness.
The result is a more stable deployment capable of supporting multiple models without permanently occupying valuable memory resources.
Built for Real Edge Deployments
OatRAG was designed around a simple philosophy:
Every megabyte saved by infrastructure is a megabyte available for inference.
To achieve this, the platform combines:
- Rust + Axum
- PostgreSQL + pgvector
- SQLite FTS5
- Parent-Child Chunking
- Reciprocal Rank Fusion (RRF)
- Automatic Model Unloading
Together, these design decisions maximize the usable memory available to language models while maintaining enterprise-grade retrieval quality.
Final Takeaway
Building efficient AI systems is no longer just about choosing the right model.
As models become smaller, faster, and more capable, the infrastructure around them increasingly determines what can actually run on edge hardware.
OatRAG was built around a simple idea:
Infrastructure should consume as little memory as possible so that models can consume as much as necessary.
By replacing heavyweight runtimes with native Rust services, reducing dependency overhead, and combining lightweight retrieval technologies, OatRAG turns an 8GB Jetson Orin Nano into a capable enterprise RAG platform.
The result isn't just lower memory usage.
It's more room for better models, larger context windows, and future growth on the same hardware.
FAQ
Common questions
What is OatRAG?
OatRAG is a lightweight Retrieval-Augmented Generation (RAG) platform built specifically for resource-constrained environments. It combines Rust, PostgreSQL + pgvector, SQLite FTS5, and hybrid retrieval techniques to deliver enterprise-grade AI search with an extremely small memory footprint.
How much memory does OatRAG consume on Jetson Orin Nano?
During benchmarking, the complete OatRAG infrastructure stack—including backend APIs, vector database, analytics, and frontend delivery—consumed only 90.36 MB of RAM, leaving approximately 84.8% of the Jetson Orin Nano's memory available for model inference.
Why does OatRAG use PostgreSQL + pgvector instead of ChromaDB?
PostgreSQL with pgvector provides enterprise-grade vector search while avoiding the large Python runtime dependencies typically required by ChromaDB. This significantly reduces memory overhead and simplifies deployment.
Why was Rust chosen instead of Node.js or Python?
Rust provides native compiled performance, predictable memory usage, zero garbage collection pauses, and highly efficient concurrency. These characteristics make it ideal for edge AI deployments where every megabyte matters.
Can OatRAG run outside Jetson Orin Nano?
Yes. While optimized for edge AI deployments, OatRAG can also be deployed on cloud servers, on-premise infrastructure, industrial gateways, and other Linux-based environments.
Can you run RAG on a Jetson Orin Nano?
Yes. We ran a full production RAG stack—vector database, hybrid retrieval, API, and UI—on an 8GB NVIDIA Jetson Orin Nano using only 90.36 MB of RAM, leaving about 6.45 GB (84.8%) free for the language model.
How much memory does an edge RAG stack need?
A conventional RAG stack (Next.js, Express, ChromaDB, Python) uses roughly 595 MB before inference even starts. A Rust + PostgreSQL/pgvector stack like OatRAG delivers the same retrieval in about 90 MB—an 84.8% reduction—so most of the device's memory stays available for the model.
Related